
Private AI 4.0 – Named Entity Recognition
Introducing Private AI's Named Entity Recognition (NER) Route: Enhance Risk Assessments with Entity Detection
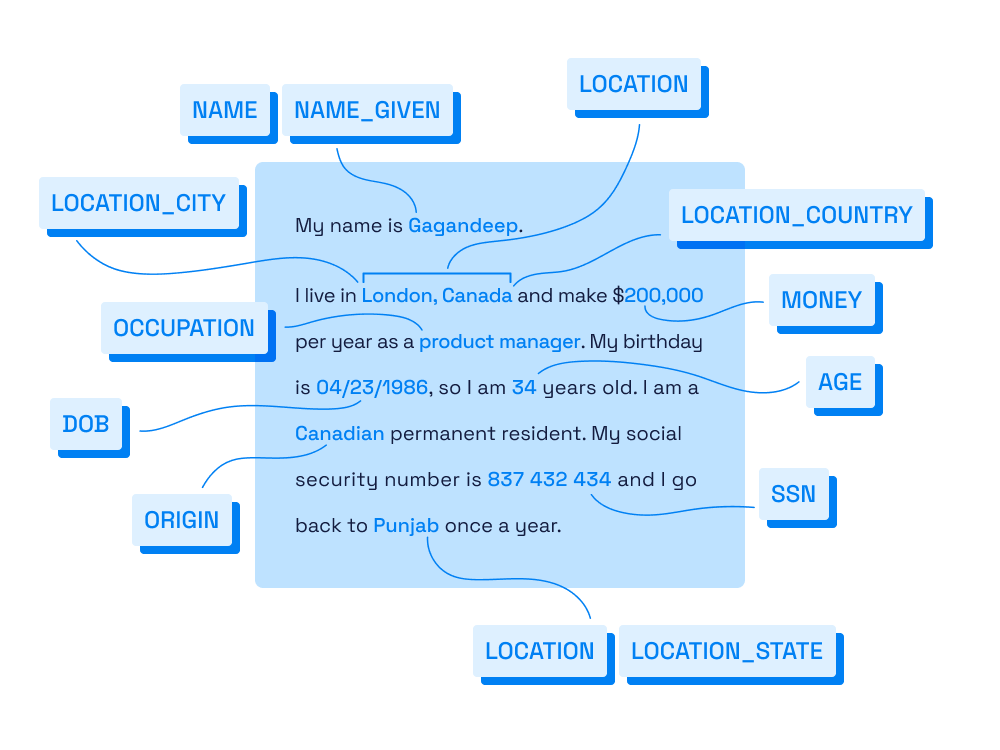
At Private AI, we help healthcare organizations utilize the full potential of their data while ensuring it remains private, secure, and compliant. With our release of Private AI 4.0, we’re introducing the Named Entity Recognition (NER) Route—a specialized tool designed to detect and extract key entities from unstructured sensitive and health data. Whether you’re managing clinical data, patient interactions, or insurance documents, our NER Route enables you to identify sensitive information without modifying the original text—supporting compliance, risk mitigation, and operational efficiency.
Built to recognize PHI, PII, PCI and Confidential Company Information (CCI) across 50+ languages, our NER Route helps healthcare professionals, researchers, insurers, and more gain valuable insights while protecting patient privacy.
What Sets Our NER Route Apart?
Our existing Process_Text route provides both entity detection and automated redaction, ensuring compliance by removing protected health information (PHI).
The new NER Route, however, is designed for healthcare organizations that need precise entity detection without altering the original text. By extracting only the detected entities, the NER Rouge enables faster, more effective risk assessments and compliance reviews.
- • NER Route – Returns only the detected entities, making it ideal for healthcare risk assessments, claims processing, and regulatory compliance.
- • Process_Text Route – Provides detected entities along with a redacted version of the text, ensuring automated PHI removal for organizations prioritizing privacy-first workflows.
Ideal Applications for the NER Route
• Privacy & Compliance Audits: Identify PHI, PII, and other sensitive data in clinical documentation to ensure compliance with HIPAA, GDPR, and other healthcare regulations.
• Risk & Security Assessments – Detect financial and patient data vulnerabilities, helping healthcare organizations strengthen cybersecurity protections.
• Medical Research & Data Governance – Understand where PHI resides across multi-language datasets, ensuring proper handling of sensitive health information.
• Operational Efficiency in Healthcare Workflows – Analyze large volumes of patient records to extract meaningful insights, streamline administrative processes, and enhance decision-making.
Why Choose Private AI’s NER Route?
✓ Comprehensive Coverage Across Health Data Types and Languages: Detect PHI, PII, PCI, and CCI in over 50 languages, ensuring that your healthcare risk assessments are thorough, inclusive, and applicable to a global data environment.
✓ Efficient PHI Detection: Swiftly identify sensitive health information, streamlining privacy impact assessments and compliance with healthcare regulations like HIPAA, ensuring that data protection is always a priority.
✓ Granular and Actionable Data Insights: Access detailed entity detection for sensitive health data, enabling customized approaches to compliance, risk management, and data protection to better meet your organization’s needs.
✓ Drive Informed Healthcare Compliance and Security Strategies: Gain deeper insights into your health data to inform healthcare policies, compliance strategies, and security measures, ensuring that sensitive data is handled with the utmost care.
Benefits of Using Our NER Route
Broad Language Support:
Detect PHI, PII, and CCI across 50+ languages, ensuring global healthcare organizations can accurately identify sensitive data.
Rapid Risk Identification:
Quickly determine if patient health information (PHI) or financial data is present, enabling proactive compliance efforts and risk mitigation.
Streamlined Data Processing:
Focus only on the extracted entities, significantly reducing the time and resources needed for manual reviews and regulatory reporting.
Enhanced Compliance & Security:
Support HIPAA, GDPR, and other regulatory requirements by accurately identifying protected health information (PHI) and confidential data, ensuring secure and compliant data handling.