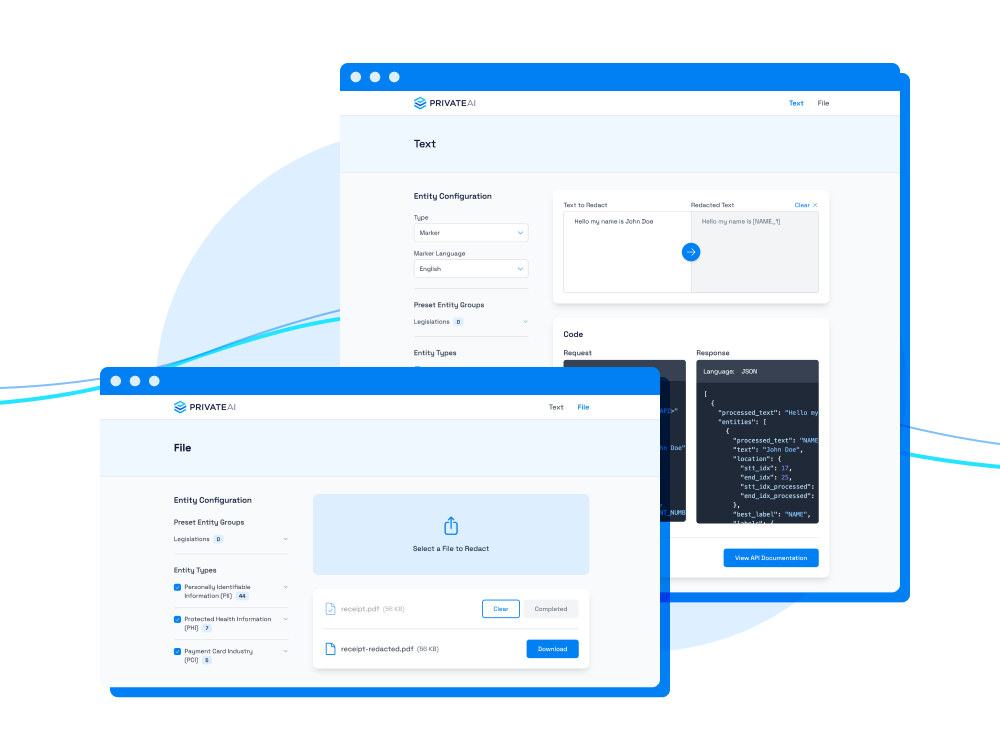

Private AI’s Container Playground puts privacy testing and fine-tuning directly in your hands. This controlled environment allows teams to experiment with de-identification, entity recognition, and redaction settings—ensuring compliance, accuracy, and seamless deployment before moving to production.
Quickly test and optimize privacy settings to ensure compliance with HIPAA, PCI, and other regulatory standards—without exposing real data.
Fine-tune privacy settings to preserve data value while safeguarding sensitive information, enabling seamless integration into enterprise workflows.
Empower teams with hands-on testing in a controlled environment, ensuring faster, risk-free deployment into production systems.
With the Container Playground, you can see firsthand how Private AI safeguards PHI, PII, and PCI in real-world healthcare scenarios—all within your own secure environment. This hands-on experience allows you to test Private AI’s health data designed entity recognition and de-identification, adjust configurations in real time, and gain critical insights to optimize your data privacy strategy while ensuring compliance with HIPAA, GDPR, and other healthcare regulations.
Fill out the form below and we’ll send you a free API key for 500 calls (approx. 50k words). No commitment, no credit card required!
Expand the categories below to see which languages are included within each language pack.
Note: English capabilities are automatically included within the Enterprise pricing tier.
French
Spanish
Portuguese
Arabic
Hebrew
Persian (Farsi)
Swahili
French
German
Italian
Portuguese
Russian
Spanish
Ukrainian
Belarusian
Bulgarian
Catalan
Croatian
Czech
Danish
Dutch
Estonian
Finnish
Greek
Hungarian
Icelandic
Latvian
Lithuanian
Luxembourgish
Polish
Romanian
Slovak
Slovenian
Swedish
Turkish
Hindi
Korean
Tagalog
Bengali
Burmese
Indonesian
Khmer
Japanese
Malay
Moldovan
Norwegian (Bokmål)
Punjabi
Tamil
Thai
Vietnamese
Mandarin (simplified)
Arabic
Belarusian
Bengali
Bulgarian
Burmese
Catalan
Croatian
Czech
Danish
Dutch
Estonian
Finnish
French
German
Greek
Hebrew
Hindi
Hungarian
Icelandic
Indonesian
Italian
Japanese
Khmer
Korean
Latvian
Lithuanian
Luxembourgish
Malay
Mandarin (simplified)
Moldovan
Norwegian (Bokmål)
Persian (Farsi)
Polish
Portuguese
Punjabi
Romanian
Russian
Slovak
Slovenian
Spanish
Swahili
Swedish
Tagalog
Tamil
Thai
Turkish
Ukrainian
Vietnamese
Testé sur un ensemble de données composé de données conversationnelles désordonnées contenant des informations de santé sensibles. Téléchargez notre livre blanc pour plus de détails, ainsi que nos performances en termes d’exactitude et de score F1, ou contactez-nous pour obtenir une copie du code d’évaluation.
Number quoted is the number of PII words missed as a fraction of total number of words. Computed on a 268 thousand word internal test dataset, comprising data from over 50 different sources, including web scrapes, emails and ASR transcripts.
Please contact us for a copy of the code used to compute these metrics, try it yourself here, or download our whitepaper.