

TL;DR: I showcase some techniques to improve DALI resource usage & create a completely CPU-based pipeline. These techniques stabilize long-term memory usage and allow for ~50% larger batch size compared to the example CPU & GPU pipelines provided with the DALI package. Testing with a Tesla V100 accelerator shows that PyTorch+DALI can reach processing speeds of nearly 4000 images/s, ~4X faster than native PyTorch.
Update 20/3/2019: DALI 0.19 features improved memory management, eliminating the gradual rise in memory usage (278). I’d still recommend to re-import DALI when using the GPU pipeline however in order to reduce GPU memory usage.
Introduction
The last couple of years have seen tremendous progress on the Deep Learning hardware front. Nvidia’s latest offerings, the Tesla V100 & Geforce RTX series, contain dedicated tensor cores to accelerate the operations commonly used in neural networks. The V100, in particular, has enough power to train neural networks at thousands of images per second, bringing single-GPU training on the ImageNet dataset down to just a few hours for small models. That’s a far cry from the 5 days it took to train the AlexNet model on ImageNet in 2012!
Such powerful GPUs strain the data preprocessing pipeline. To account for this, Tensorflow released a new data loader: tf.data.Dataset. The pipeline is written in C++ and uses a graph-based approach whereby multiple preprocessing operations are chained together to form a pipeline. PyTorch on the other hand uses a data loader written in Python on top of the PIL library — great for ease of use and flexibility, not so great for speed. Although the PIL-SIMD library does improve the situation a bit.
Enter the NVIDIA Data Loading Library (DALI): designed to remove the data preprocessing bottleneck, allowing for training and inference to run at full speed. DALI is primarily designed to do preprocessing on a GPU, but most operations also have a fast CPU implementation. This articles focuses on PyTorch, however DALI also supports Tensorflow, MXNet & TensorRT. TensorRT support, in particular, is great. It allows for both the training and inference steps to use the exact same preprocessing code. Different frameworks like Tensorflow & PyTorch typically feature small differences between the data loaders, which might end up affecting accuracy.
Below are some great resources to get started with DALI:
DALI Home
Fast AI Data Preprocessing with NVIDIA DALI
DALI Developer Guide
For the remainder of this article I’m going to assume a basic familiarity with ImageNet preprocessing and the DALI ImageNet example. I’ll discuss some issues that I ran up against whilst using DALI, along with how I got around them. We’ll look at both CPU and GPU pipelines.
DALI Long-Term Memory Usage
Update 20/3/2019: This issue has been fixed in DALI 0.19
The first issue I encountered with DALI is that RAM usage increases with every training epoch, causing OOM errors (even on a VM with 78GB RAM). This has been flagged (278, 344, 486), but has yet to be fixed.

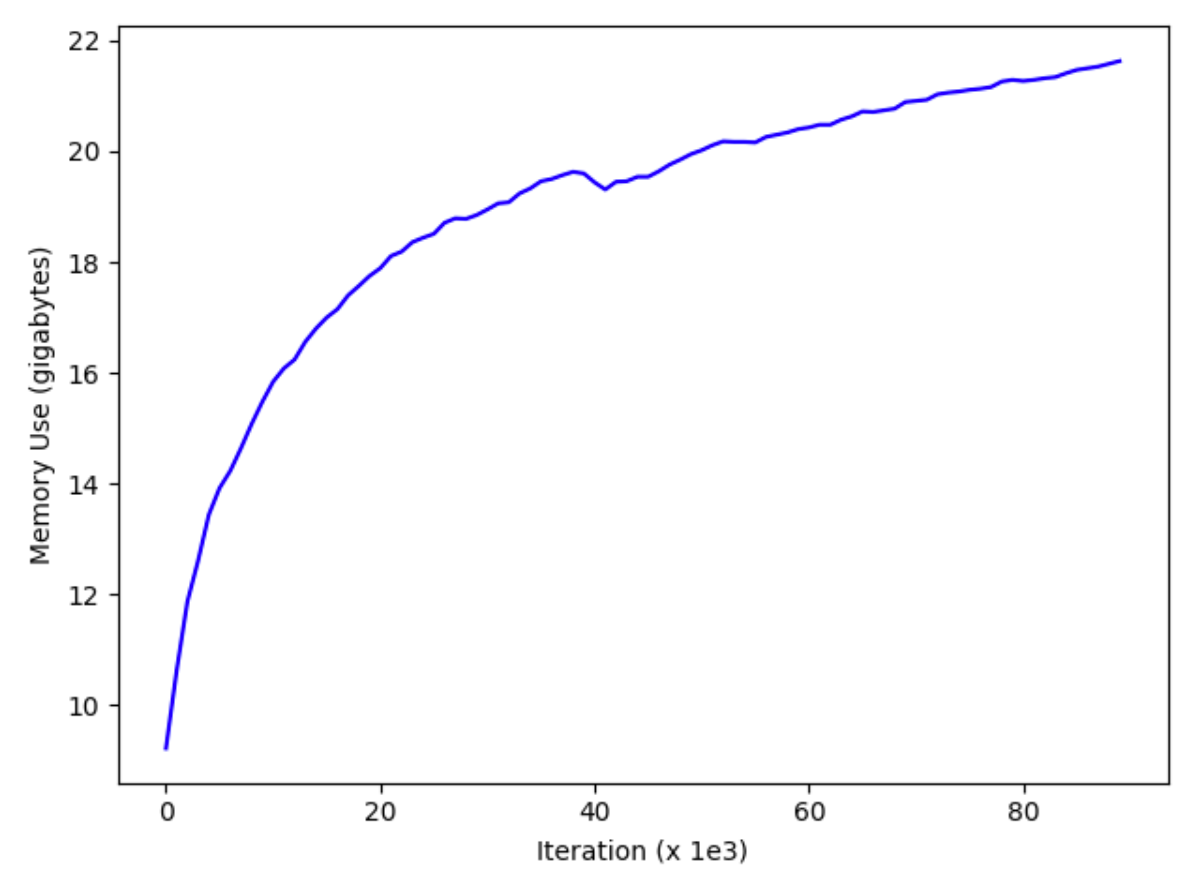
The only solution I could find wasn’t pretty — reimport DALI & recreate the train & validation pipelines at every epoch:
del self.train_loader, self.val_loader, self.train_pipe, self.val_pipe
torch.cuda.synchronize()
torch.cuda.empty_cache()
gc.collect()importlib.reload(dali)
from dali import HybridTrainPipe, HybridValPipe, DaliIteratorCPU, DaliIteratorGPU
Note that, with this workaround, DALI still requires a lot of RAM to get the best results. Given how cheap RAM is nowadays (relative to Nvidia GPUs at least) this isn’t much of a concern; rather, GPU memory is more of a problem. As can be seen from the table below, the maximum batch size possible whilst using DALI is as much as 50% lower than TorchVision:

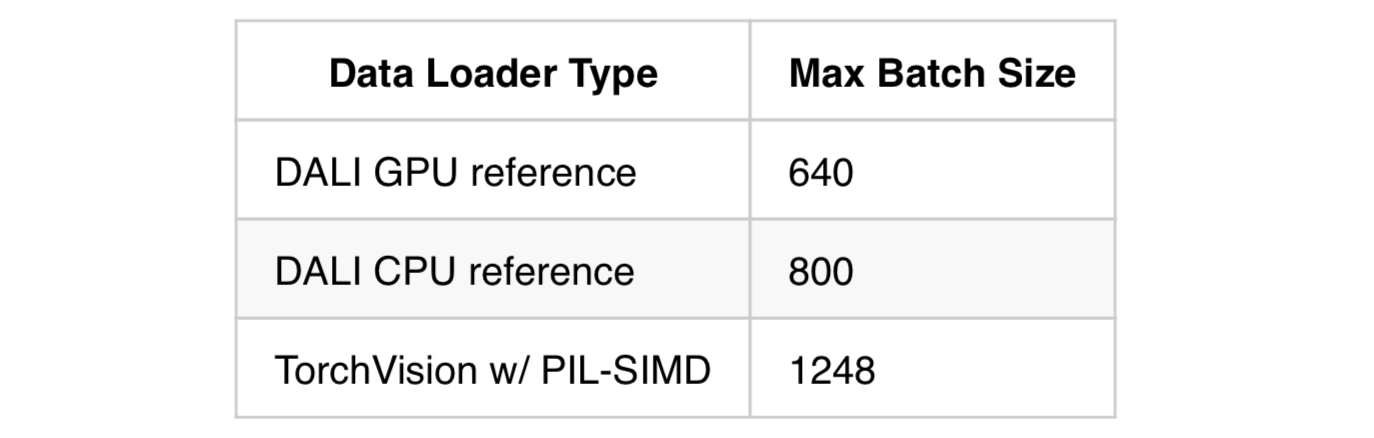
In the following sections, I’ll cover some approaches to reduce GPU memory usage.
Building a Completely CPU-based Pipeline
Let’s look at the example CPU pipeline first. The CPU-based pipeline is useful for when peak throughput isn’t required (e.g., when working with medium & large sized models like ResNet50). The CPU training pipeline only does the decoding & resizing operations on CPU however, with the CropMirrorNormalize operation running on GPU. This is significant. I found that even just transferring the output to GPU with DALI used a lot of GPU memory. To circumvent this, I modified the example CPU pipeline to run entirely on CPU:
class HybridTrainPipe(Pipeline):
def __init__(self, batch_size, num_threads, device_id, data_dir, crop,
mean, std, local_rank=0, world_size=1, dali_cpu=False, shuffle=True, fp16=False,
min_crop_size=0.08):
# As we're recreating the Pipeline at every epoch, the seed must be -1 (random seed)
super(HybridTrainPipe, self).__init__(batch_size, num_threads, device_id, seed=-1)
# Enabling read_ahead slowed down processing ~40%
self.input = ops.FileReader(file_root=data_dir, shard_id=local_rank, num_shards=world_size,
random_shuffle=shuffle)
# Let user decide which pipeline works best with the chosen model
if dali_cpu:
decode_device = "cpu"
self.dali_device = "cpu"
self.flip = ops.Flip(device=self.dali_device)
else:
decode_device = "mixed"
self.dali_device = "gpu"
output_dtype = types.FLOAT
if self.dali_device == "gpu" and fp16:
output_dtype = types.FLOAT16
self.cmn = ops.CropMirrorNormalize(device="gpu",
output_dtype=output_dtype,
output_layout=types.NCHW,
crop=(crop, crop),
image_type=types.RGB,
mean=mean,
std=std,)
# To be able to handle all images from full-sized ImageNet, this padding sets the size of the internal nvJPEG buffers without additional reallocations
device_memory_padding = 211025920 if decode_device == 'mixed' else 0
host_memory_padding = 140544512 if decode_device == 'mixed' else 0
self.decode = ops.ImageDecoderRandomCrop(device=decode_device, output_type=types.RGB,
device_memory_padding=device_memory_padding,
host_memory_padding=host_memory_padding,
random_aspect_ratio=[0.8, 1.25],
random_area=[min_crop_size, 1.0],
num_attempts=100)
# Resize as desired. To match torchvision data loader, use triangular interpolation.
self.res = ops.Resize(device=self.dali_device, resize_x=crop, resize_y=crop,
interp_type=types.INTERP_TRIANGULAR)
self.coin = ops.CoinFlip(probability=0.5)
print('DALI "{0}" variant'.format(self.dali_device))
def define_graph(self):
rng = self.coin()
self.jpegs, self.labels = self.input(name="Reader")
# Combined decode & random crop
images = self.decode(self.jpegs)
# Resize as desired
images = self.res(images)
if self.dali_device == "gpu":
output = self.cmn(images, mirror=rng)
else:
# CPU backend uses torch to apply mean & std
output = self.flip(images, horizontal=rng)
self.labels = self.labels.gpu()
return [output, self.labels]The DALI pipeline now outputs an 8-bit tensor on the CPU. We need to use PyTorch to do the CPU-> GPU transfer, the conversion to floating point numbers, and the normalization. These last two ops are done on GPU, given that, in practice, they’re very fast and they reduce the CPU -> GPU memory bandwidth requirement. I tried pinning the tensor before transferring to GPU, but didn’t manage to get any performance uplift from doing so. Putting it together with a prefetcher:
def _preproc_worker(dali_iterator, cuda_stream, fp16, mean, std, output_queue, proc_next_input, done_event, pin_memory):
"""
Worker function to parse DALI output & apply final preprocessing steps
"""
while not done_event.is_set():
# Wait until main thread signals to proc_next_input -- normally once it has taken the last processed input
proc_next_input.wait()
proc_next_input.clear()
if done_event.is_set():
print('Shutting down preproc thread')
break
try:
data = next(dali_iterator)
# Decode the data output
input_orig = data[0]['data']
target = data[0]['label'].squeeze().long() # DALI should already output target on device
# Copy to GPU and apply final processing in separate CUDA stream
with torch.cuda.stream(cuda_stream):
input = input_orig
if pin_memory:
input = input.pin_memory()
del input_orig # Save memory
input = input.cuda(non_blocking=True)
input = input.permute(0, 3, 1, 2)
# Input tensor is kept as 8-bit integer for transfer to GPU, to save bandwidth
if fp16:
input = input.half()
else:
input = input.float()
input = input.sub_(mean).div_(std)
# Put the result on the queue
output_queue.put((input, target))
except StopIteration:
print('Resetting DALI loader')
dali_iterator.reset()
output_queue.put(None)
class DaliIteratorCPU(DaliIterator):
"""
Wrapper class to decode the DALI iterator output & provide iterator that functions in the same way as TorchVision.
Note that permutation to channels first, converting from 8-bit integer to float & normalization are all performed on GPU
pipelines (Pipeline): DALI pipelines
size (int): Number of examples in set
fp16 (bool): Use fp16 as output format, f32 otherwise
mean (tuple): Image mean value for each channel
std (tuple): Image standard deviation value for each channel
pin_memory (bool): Transfer input tensor to pinned memory, before moving to GPU
"""
def __init__(self, fp16=False, mean=(0., 0., 0.), std=(1., 1., 1.), pin_memory=True, **kwargs):
super().__init__(**kwargs)
print('Using DALI CPU iterator')
self.stream = torch.cuda.Stream()
self.fp16 = fp16
self.mean = torch.tensor(mean).cuda().view(1, 3, 1, 1)
self.std = torch.tensor(std).cuda().view(1, 3, 1, 1)
self.pin_memory = pin_memory
if self.fp16:
self.mean = self.mean.half()
self.std = self.std.half()
self.proc_next_input = Event()
self.done_event = Event()
self.output_queue = queue.Queue(maxsize=5)
self.preproc_thread = threading.Thread(
target=_preproc_worker,
kwargs={'dali_iterator': self._dali_iterator, 'cuda_stream': self.stream, 'fp16': self.fp16, 'mean': self.mean, 'std': self.std, 'proc_next_input': self.proc_next_input, 'done_event': self.done_event, 'output_queue': self.output_queue, 'pin_memory': self.pin_memory})
self.preproc_thread.daemon = True
self.preproc_thread.start()
self.proc_next_input.set()
def __next__(self):
torch.cuda.current_stream().wait_stream(self.stream)
data = self.output_queue.get()
self.proc_next_input.set()
if data is None:
raise StopIteration
return data
def __del__(self):
self.done_event.set()
self.proc_next_input.set()
torch.cuda.current_stream().wait_stream(self.stream)
self.preproc_thread.join()GPU-Based Pipeline
In my testing, the new full CPU pipeline detailed above is about twice as fast as TorchVision’s data loader, whilst achieving nearly the same maximum batch size. The CPU pipeline works great with large models like ResNet50; however, when using small models like AlexNet or ResNet18, the CPU pipeline still isn’t able to keep up with the GPU. For these cases, the example GPU pipeline works best. The trouble is that the GPU pipeline reduces the maximum possible batch size by almost 50%, limiting throughput.
One way to significantly reduce GPU memory usage is by keeping the validation pipeline off the GPU until it’s actually needed at the end of an epoch. This is easy to do as we’re already reimporting the DALI library and recreating data loaders at every epoch.
More Tips
More tips for using DALI:
* For validation, a batch size that evenly divides the dataset size works best e.g. 500 instead of 512 for a validation set size of 50000 — this avoids a partial batch at the end of the validation dataset.
* Similar to the Tensorflow & PyTorch data loaders, the TorchVision and DALI pipelines don’t produce bit-identical outputs — you’ll see the validation accuracies differ slightly. I found that this is due to different JPEG image decoders. There was previously an issue with resizing but this is now fixed. The flipside is that DALI supports TensorRT, allowing for the exact same preprocessing to be used for training & inference.
* For peak throughput, try setting the number of data loader workers to number_of_virtual_CPU cores. 2 gave the best performance (2 virtual cores = 1 physical core)
* If you want absolute best performance and don’t care about having outputs similar to TorchVision, try turning off triangular interpolation on the DALI image resize
* Don’t forget about disk IO. Make sure you have enough RAM to cache the dataset and/or a really fast SSD. DALI can pull up to 400Mb/s from disk!
Putting it Together
To help integrate these modifications easily, I created a data loader class with all the modifications described here, including both DALI and TorchVision backends. Usage is simple. Instantiate the data loader:
dataset = Dataset(data_dir,
batch_size,
val_batch_size
workers,
use_dali,
dali_cpu,
fp16)Then get the train & validation data loaders:
train_loader = dataset.get_train_loader()
val_loader = dataset.get_val_loader()Reset the data loader at the end of every training epoch:
dataset.reset()Optionally, the validation pipeline can be recreated on GPU prior to model validation:
dataset.prep_for_val()Benchmarks
Here are the max batch sizes I was able to use with ResNet18:


So, by applying these modifications, the max batch size DALI can use in both CPU & GPU modes is increased by ~50%!
Here are some throughput figures with Shufflenet V2 0.5 & batch size 512:

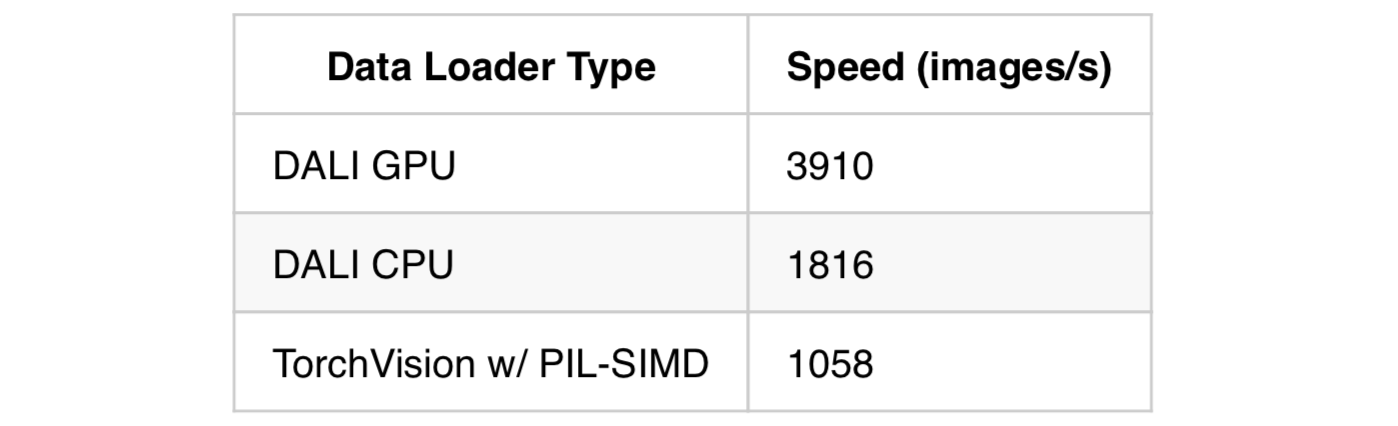
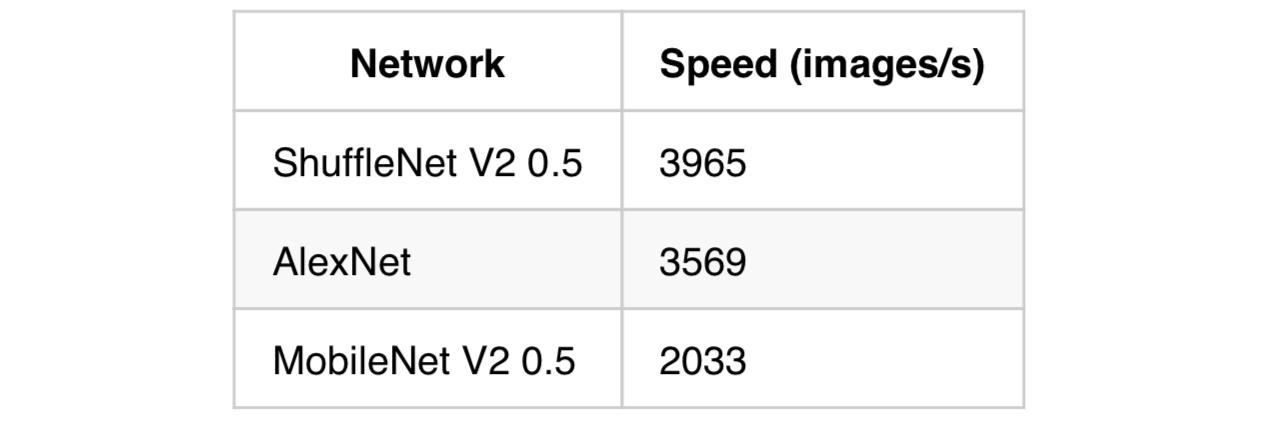
And here are some results of using the DALI GPU pipeline to train various networks included in TorchVision:

All tests were run on a Google Cloud V100 instance with 12 vCPUs (6 physical cores), 78GB RAM & using Apex FP16 training. To reproduce these results, use the following arguments:
— fp16 — batch-size 512 — workers 10 — arch “shufflenet_v2_x0_5 or resnet18” — prof — use-dali
So, with DALI, a single Tesla V100 can reach speeds of nearly 4000 image/s! That’s just over half of what Nvidia’s super expensive DGX-1 with 8 V100 GPUs can do (albeit using small models). For me, being able to do an ImageNet training run on a single GPU in a few hours was a productivity game changer. Hopefully it will be for you as well. Feedback appreciated!
The code presented in this article is here
Acknowledgements
Many thanks to Patricia Thaine for her feedback on an earlier draft of this post.
Cover image by Jacek Abramowicz

