

Identifier, rédiger et remplacer les informations personnellement identifiables dans les textes non structurés

Vos données, comme vous le voulez
Nous appliquons les dernières avancées en matière d’architectures de transformeurs pour relever les données à caractère personnel (DCP) en nous basant entièrement sur le contexte, ce qui nous rend particulièrement efficaces sur les données semi-structurées et non structurées.
Avec Private AI, les équipes chargées des données, de la sécurité et de l’apprentissage automatique peuvent :
- Atteindre une précision inégalée sur des données telles que les transcriptions de reconnaissance vocale, les discussions sur les chats et les dossiers médicaux électroniques.
- Conserver l'entière propriété de vos données ; elles ne sont jamais partagées avec nous et ne quittent jamais votre infrastructure (contrairement aux grands fournisseurs de cloud computing, nos CGV le confirment).
- Identifiez et rédigez le texte dans 49 langues (et plus encore à venir).
- Configurez la prise en charge, notamment en activant ou désactivant des entités, en ajoutant des listes de blocage ou d'autorisation, et en vous conformant aux réglementations en matière de confidentialité telles que RGPD, LGPD, PIPEDA, etc.
- Des types d'entités personnalisées délivrés rapidement, grâce aux techniques d'apprentissage en peu d’essais utilisées par Private AI.
Conçu par des experts de :

Comment cela fonctionne-t-il ?
Private AI est déployée via un conteneur unique sur site afin que vous puissiez facilement ajouter nos capacités de rédaction à votre flux de données. Le conteneur est accessible via un API REST et peut être facilement personnalisé en fonction des besoins de votre équipe.
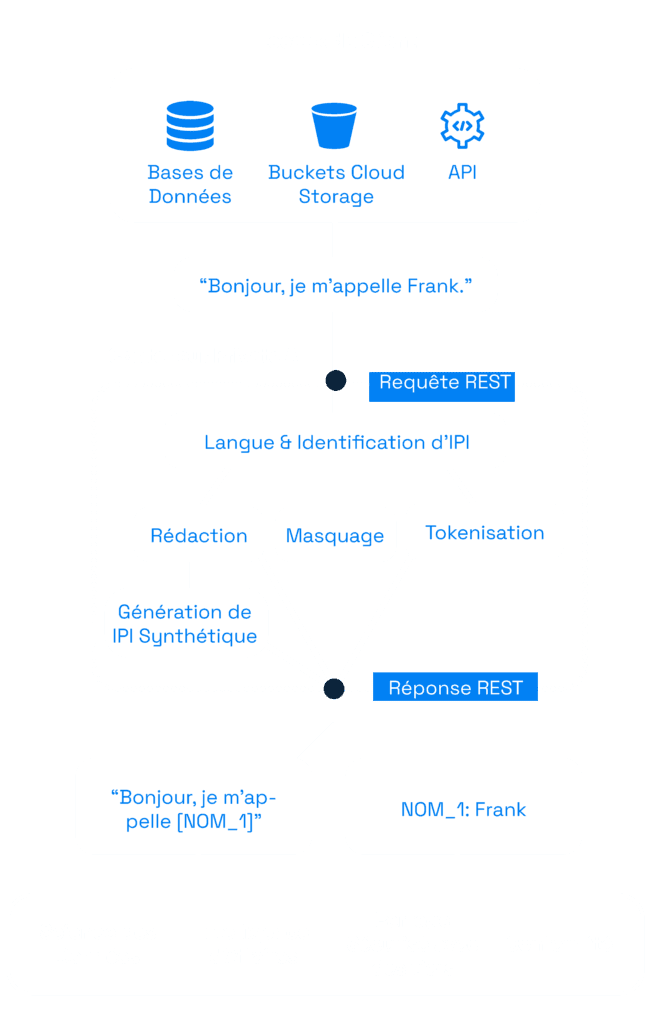
Identification des DCP
La Confidentialité est plus qu'un Modèle de Machine Learning
Private AI détecte plus de 50 types d’entités différentes d’informations personnellement identifiables (IPI) dans 52 langues. Grâce à nos modèles de Machine Learning, nous allons au-delà de la détection traditionnelle des entités pour reconnaître de nombreux types différents d’identifiants directs et de quasi-identifiants.
Ce qu’est ou n’est pas une IPI peut être compliqué, c’est pourquoi l’équipe d’experts en confidentialité de Private AI veille à ce que notre système fonctionne en conformité avec les différentes législations telles que le RGPD, la CPRA et l’HIPAA.
Private AI peut être facilement mis en œuvre pour filtrer les IPI dans n’importe quel flux de données ou base de données.
{
"result": "Hi [NAME_1], [NAME_2] this side. It's been a while since we last met in [LOCATION_CITY_1].",
"result_fake": null,
"pii": [
{
"marker": "NAME_1",
"text": "John",
"best_label": "NAME",
"stt_idx": 3,
"end_idx": 7,
"labels": {
"NAME": 0.8446
}
},
{
"marker": "NAME_2",
"text": "Grace",
"best_label": "NAME",
"stt_idx": 9,
"end_idx": 14,
"labels": {
"NAME": 0.8399
}
},
{
"marker": "LOCATION_CITY_1",
"text": "Berlin",
"best_label": "LOCATION_CITY",
"stt_idx": 63,
"end_idx": 69,
"labels": {
"LOCATION_CITY": 0.8778,
"LOCATION": 0.8512
}
}
],
"api_calls_used": 1,
"output_checks_passed": true
}


Désidentification de texte
Rédiger avec une précision supérieure à celle d'un humain
Private AI peut remplacer tous les IPI détectées par des identifiants uniques (par exemple NAME_1, CVV_3, CREDIT_CARD_2) pour produire des transcriptions propres ou des données dépersonnalisées. Vous pouvez également remplacer les IPI par un caractère de masque. Consultez notre documentation pour en savoir plus.
- Précision inégalée
- Plus de 50 types d'entités
- 52 langues (et plus à venir)
- Traite 70 000 mots/seconde
- Aucun accès tiers
- Pas de regex
- Rédaction en temps réel
- Conforme aux normes RGPD, HIPAA, CPRA, etc.
Génération Synthétique de IPI
N'utilisez jamais de transformeurs sans atténuation à la confidentialité
Une fois les IPI supprimés, Private AI peut générer des IPI synthétiques pour les remplacer par de fausses données qui correspondent au contexte environnant.
Le générateur de IPI synthétiques ne voit jamais les données originales, ce qui élimine les fuites de données personnelles et sensibles. Le texte qui en résulte réduit encore le risque de réidentification, car un adversaire doit d’abord identifier les IPI réels. Impossible de les retrouver ainsi !
Prendre des données de production et remplacer tous les IPI par des données synthétiques minimise également le décalage des données par rapport aux données d’origine, ce qui est très utile lors de la création de modèles de Machine Learning.




Tokenisation et pseudonymisation
Inversez la suppression des IPI selon vos besoins
Remplacez les IPI par des jetons cryptés à l’aide de la fonction de tokenisation de Private AI. Parfois appelée pseudonymisation, la tokenisation préserve l’utilité des données tout en protégeant ce qui est personnellement identifiable.
La tokenisation est réversible, permettant ainsi de récupérer facilement les données d’origine. Contactez-nous pour obtenir de la documentation et y accéder.