

Data anonymization, de-identification, redaction, pseudonymization, and tokenization are key technologies for satisfying data protection regulations such as the GDPR and the incoming CPRA. But distinguishing between anonymization, de-identification, redaction, pseudonymization, and tokenization is more complicated than it seems: there’s enough confusion and misinformation out there to bamboozle even the most seasoned data scientist.
Anonymization vs de-identification vs redaction vs pseudonymization vs tokenization
Getting these definitions right is a crucial step towards making the right decisions for protecting and using data most effectively. We’ll look at the definitions of each and give a running practical example to visually show what each of these looks like.
Re-identification risk is often intertwined in discussions surrounding these terms. Re-identification refers to the act of determining the identity of an individual who has directly identifying information (e.g., full name, social security number) or quasi-identifying information (e.g., age, approximate address) in a dataset. Quasi-identifiers, when combined together, lead to an exponential risk of re-identification. In some cases, the ability to re-identify is desired by the de-identifying body, in which case another layer of risk lies with the potential of a malicious party to access the data linking direct and quasi-identifiers with the data they were replaced with.
Anonymization
Anonymization means removing personally identifiable information and quasi-identifiable information (i.e., data that, when combined with other information, can lead to re-identification; e.g., age, approximate address, etc.) from a dataset in such a way that individuals become permanently unidentifiable. See Anonymization and GDPR compliance; an overviewto find out how it fits into the GDPR.
Anonymization is often the preferred method for making structured medical datasets safe for sharing. What about unstructured data? Can it be anonymized? While it’s trickier to do so, the answer is yes. Here’s a sample email that’s been properly anonymized:
“Hi [NAME],
Apologies, it had ended up in my spam!
I’m booked at [TIME] tomorrow, but [TIME] would work. I’ll send an updated invite for that time. Please let me know if that doesn’t work for you.
Thank you,
[NAME]”
De-identification
De-identification also requires the removal of personal and quasi-identifier, but through a process that enables the original data to be reconnected to the de-identified result. See Guidelines for Data De-identification or Anonymization.
In practice, de-identification is often used to describe the process of removing direct identifiers (full name, address, SSN, etc.) and sometimes quasi-identifiers (age, gender, etc.) but with fewer guarantees that data can’t be linked back to an individual than anonymization has, though it’s also sometimes used as a term that encompasses anonymization as well as pseudonymization.
What’s the point, you might wonder, of de-identifying data if you can’t guarantee that they’re anonymized? That depends on the use case.
Take the anonymized email above and change it to:
“Hi [NAME_1],
Apologies, it had ended up in my spam!
I’m booked at [TIME_1] tomorrow, but [TIME_2] would work. I’ll send an updated invite for that time. Please let me know if that doesn’t work for you.
Thank you,
[NAME_2]”
And now suppose a company decided to encrypt the direct and potential identifiers associated with NAME_1, NAME_2, TIME_1, and TIME_2 and store them separately in case they ever needed to re-identify the email (perhaps for potential use in court). That email would no longer count as anonymized, because the identifiers could be linked back to it.
But that doesn’t mean that privacy has been compromised. For example, if analytics and machine learning teams are using de-identified emails (as opposed to the plaintext originals), they are actually doing their users and their company a great service. It’s possible to gain insights while mitigating user privacy risk, and also minimizing the security risk of sending personal data to another part of an organization where it might become untraceable.
Redaction
To add to the confusion between anonymization and de-identification, the term redaction is also often used erroneously. According to the International Association of Privacy Professionals’ glossary, redaction is “[t]he practice of identifying and removing or blocking information from documents being produced […]”.
Redaction plays an interesting role with respect to de-identification. Redaction doesn’t necessarily involve the full removal of personal data, but rather the selective removal of particularly sensitive information. One example is the removal of credit card numbers from customer service conversations. If emails, call transcripts, or chat logs get leaked with questions about how to use a vacuum cleaner… that’s probably not very damaging. But if there are credit card numbers in those chat logs and they haven’t been removed? HUGE deal.
Pseudonymization
Now there’s one term in particular that’s often misinterpreted; namely, pseudonymization. Pseudonymization means the replacement of certain data (e.g. a name, address, etc.) with fake data that is often represented as being linked to the original data. This has left a rather big hole to fill for a term that means replacing information with fake data that is not linked to the original data. We are going to coin the phrase natural pseudonymization without linkage to define this.
There are numerous advantages to natural pseudonymization without linkage over de-identification as represented above. For one, data becomes more friendly for machine learning training and inference. In the example below, the PII has been replaced with fake data in italics:
“Hi Kate,
Apologies, it had ended up in my spam!
I’m booked at 5pm tomorrow, but 9am would work. I’ll send an updated invite for that time. Please let me know if that doesn’t work for you.
Thank you,
Linda”
Additionally, whatever personal or quasi-identifiable information was accidentally left over becomes like a needle in a haystack to distinguish from the fake data (or more like a specific piece of hay in a haystack); e.g, suppose “Linda” had been accidentally missed when de-identifying the email above:
“Hi [NAME_1],
Apologies, it had ended up in my spam!
I’m booked at [TIME_1] tomorrow, but [TIME_2] would work. I’ll send an updated invite for that time. Please let me know if that doesn’t work for you.
Thank you,
Linda”
At Private AI, we’ve spent a significant amount of time to figure out how to do automatic pseudonymization properly. Here’s a hint: dictionary lookup doesn’t work. We’ve had to create our own transformer model architecture (a type of machine learning model built for natural language processing) in order to generate realistic words and numbers in a contextualized, non-deterministic way. Careful selection of training data was paramount to generating realistic replacements, among other tricks of the trade.
Tokenization is also often referred to as a type of pseudonymization.
Tokenization
A final term that’s often used for specifically characterizing the type of token that replaces certain data is tokenization. That is, replacing personal data with a random token. Often, a link is maintained between the original data and the token (e.g., for payment processing on websites). Tokens can, for example, be generated by one-way functions (e.g., salted hashes) or can be completely random numbers. Some types of tokenization can even be reversible if they rely on encryption, for example, in which case only the decryption key needs to be stored, rather than the link between every piece of personal data and their replacement.
Let’s tokenize the direct and quasi-identifiable information in our running email example:
“Hi 748331D230BF99D9A39ED0E6C6668CDD,
Apologies, it had ended up in my spam!
I’m booked at 3388E06178D0634FC03FFBDECCE677F8 tomorrow, but F6F7755D5141D5B7308DF2516AA9A82C would work. I’ll send an updated invite for that time. Please let me know if that doesn’t work for you.
Thank you,
CE5A40345609B81A5E7C973C1F3D93EB”
While tokenization has been particularly useful for payment processing, it is unlikely to be a winner for unstructured data protection given its relative lack of relevant contextual information compared to, say, natural pseudonymization without linkage.
Putting it all together
Despite direct and quasi-identifiers being removed in one way or another through each of anonymization, de-identification, redaction, pseudonymization, and tokenization, they’re all remarkably effective at maintaining the contextual information of the original data. Stay tuned for our next post on how anonymization is misunderstood.
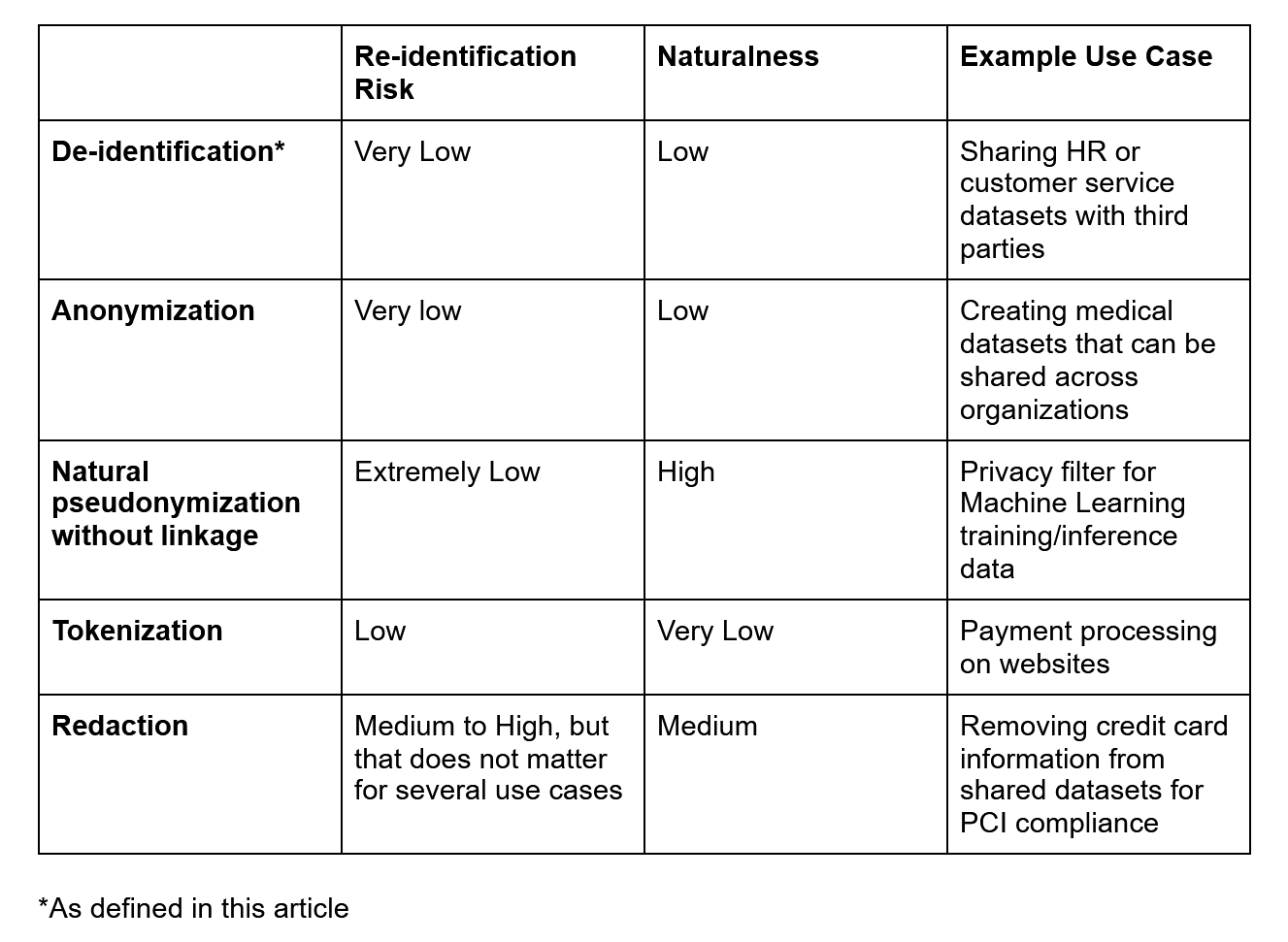
In the meantime, here’s a handy table to guide your decision-making:
Acknowledgements
Thank you to John Stocks and Pieter Luitjens for their feedback on earlier drafts of this post.

