

Data protection is a critical concern in today’s digital world. As more and more data are collected and processed, the need for effective data protection measures becomes increasingly important. Structured, semi-structured, and unstructured data all present unique challenges for data protection, and it’s essential to understand the differences between them in order to implement effective protection measures.
Structured Data
Structured data are data that are organized and formatted in a specific way, allowing viewers to understand immediately what type of data they are looking at. Meticulously labelled bank transaction information is a good example of structured data, and so is email metadata, including the sender, receiver, route, time of sending etc. This kind of data usually lives in spreadsheets, tables, or databases, e.g., Structured Query Language (SQL).
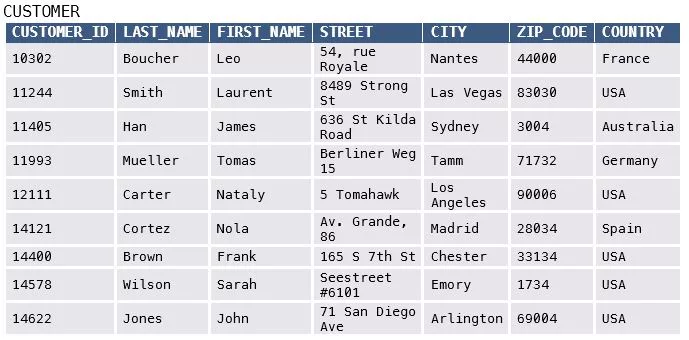
Image source: https://www.michael-gramlich.com/what-is-structured-semi-structured-and-unstructured-data/
Challenges with Processing and Protecting Structured Data
Because structured data has a clear organization, it is typically easier to manage and protect the Personally Identifiable Information (PII) within this type of data. Yet, some challenges remain:
Complexity of Data Mappings: While structured data is easier to navigate and understand than other types of data, creating an organizational data map can be a complex and time-consuming process. When dealing with large datasets, it can be difficult to track relationships between tables and fields, and to ensure that each piece of PII is accurately labeled, accounted for, and linked to a unique identifier.
Merging Tables with Inconsistent Unique Identifiers: Structured data often contains data across multiple tables or databases, and these tables may have inconsistent unique identifiers or other variations that make it challenging to combine data from different sources. This can lead to incomplete or inaccurate data maps, or data that is difficult to work with.
Mislabeling of Data: Structured data may also contain errors or mislabeled data, which can lead to incorrect analyses and conclusions. Data may be mislabeled due to human error, inconsistencies in labeling standards, or other factors. This can make it challenging to ensure the accuracy and reliability of structured database schemas, especially when working with large datasets.
Definition: A database schema defines the rules and constraints for the data that is stored in the database, including the data types, formats, and allowable values for each field. It also specifies the relationships between tables, such as which fields are primary keys and which fields are foreign keys.
For example, if a specific dataset is supposed to be disclosed to a third party but without all the SIN numbers in that dataset, the column that contains the SIN numbers can simply be dropped before the transfer. The risk that remains, however, is that a SIN number was inadvertently inputted in the wrong place, e.g., in a phone number field. It is therefore important to run the data through a program that is able to recognize any data types that have inadvertently remained in the data that will be disclosed.
Unstructured Data
Unstructured data present more significant challenges when it comes to data protection. Unstructured data has no specific organization or format. Examples of unstructured data include text documents like pdfs, docx, emails, call audio recordings, etc., but also images and videos.
Image source: https://aibidia.com/what-are-transfer-pricing-data-points-and-5-reasons-to-have-them-structured/
Challenges with Processing and Protecting Unstructured Data
Due to its complexity, unstructured and semi-structured data pose a considerable challenge to organizations wishing to process and protect PII within them. These challenges can be categorized as follows:
Lack of Standardization: Unstructured data lacks standard labelling, making it difficult to categorize and organize. This can lead to inconsistent data quality, incomplete data sets, and difficulties in interpreting the data.
Volume and Velocity: Unstructured data are often large in volume and can be created and updated rapidly. This can make it challenging to process and analyze the data either in real-time or to process them cost-effectively in batches.
Security Risks: Unstructured data can pose significant security risks, as PII may be scattered across multiple files and formats. This can make it difficult to identify and protect all personal data and leave organizations vulnerable to data breaches and other security threats.
To manage and protect unstructured data effectively, AI technologies are instrumental. AI can help automate the process of extracting and analyzing relevant information from unstructured data, while also detecting and redacting personal information to ensure that it is properly protected. Additionally, AI can help identify patterns and anomalies within idiosyncratic unstructured data, enabling organizations to better understand their data and identify potential security risks.
Let’s say that an organization collects customer feedback through various unstructured data sources, such as email correspondence, social media messages, and online reviews. This unstructured data may be challenging to analyze and understand due to the idiosyncratic nature of human language itself, even including multiple languages within one message, mixed media types, and the volume of data that needs to be processed.
However, by using AI algorithms to analyze this unstructured data, organizations can identify patterns and anomalies that reveal important insights into customer sentiment and potential security risks. For example, the organization might discover that a significant number of customers are complaining about a specific security issue or that a particular type of feedback is associated with a high rate of fraudulent activity.
By identifying these patterns and anomalies, the organization can take proactive steps to address security risks and improve customer satisfaction. For example, they might implement new security measures to address the identified vulnerability or change their customer service processes to better respond to common issues.
Semi-Structured Data
Semi-structured data are types of data that do not have the structured format that we associate with traditional relational databases or other forms of data tables. Instead, it contains tags and metadata that help to separate different elements of the data and establish a hierarchy of records and fields.
Take an organization that collects data from their website in the form of customer reviews. These reviews contain unstructured text, but they also include some structured data, such as the date of the review and the product that was reviewed. This data has a semi-structured format because it contains some structure, but it is not organized into a traditional relational database or other forms of data tables.
To analyze this semi-structured data, the organization might use a machine learning algorithm that can extract relevant data elements, such as the product name, review text, and rating, from each review. This algorithm might rely on the tags and metadata within the semi-structured data to separate different elements of the data and establish a hierarchy of records and fields.
Semi-structured data can also refer to a combination of structured and unstructured data. Examples are (1) a database that contains a “Notes” section, (2) an excel spreadsheet that contains a table of transaction information and pictures of relevant information like receipts. Semi-structured data include XML and JSON files.
Challenges with Processing and Protecting Semi-Structured Data
The challenges with processing and protecting semi-structured data overlap to some extent with the challenges posed by both structured and unstructured data, but some are unique as well.
Variability of data structures: The data structures can be highly variable, and data elements within the same dataset may have different formats or may be organized in different ways. Semi-structured data can also be ambiguous in nature, so the content of data elements may be open to interpretation or may change over time. This variability and ambiguity can make it challenging to extract and process data in a consistent and automated way, which can lead to incomplete or inaccurate data mappings and risk assessments.
Complex relationships: Semi-structured data is often used to represent complex relationships between data elements. For example, an XML file might include nested tags and elements that reflect a hierarchical relationship between pieces of information. This complexity can make it challenging to identify and extract relevant data, and to maintain the integrity of relationships between data elements.
Data volume: Like unstructured data, semi-structured datasets can be quite large, especially in cases where they are used to represent complex relationships or models. This volume can make it challenging to process data efficiently and in a timely manner.
How Private AI Can Help You Expand Your Protection of Semi- and Unstructured Data
Private AI offers advanced AI-based PII identification and redaction software that can be used to audit and protect semi- and unstructured data effectively. Using the latest advancements in transformer architectures, Private AI identifies 50+ entities of PII in 47 languages based on context, accurately identifying PII even in the messiest of datasets. After identifying and anonymizing PII, Private AI can also generate hyper-realistic synthetic PII to replace the original information, making datasets that look and act exactly like production data without risking exposure when training ML models. Private AI’s industry-leading technology deploys via a container on premise so client data never leaves their environment and is never shared with a third party.
To see the tech in action, try our web demo, or request an API key to try it yourself on your own data.

